This is another example of how KNIME can meet even the more demanding ETL workflow requirements you may come across. The depth, breadth, and speed of KNIME’s features and functions continue to amaze me and my customers.
Processing Large Datasets With KNIME
I was recently tasked with ingesting several large zip files (over 5G) into our Anticipatory Intelligence tool workflow. When processing files for our tool we download the data and store it in the data lake for future processing. When we need to process the raw data we then grab the file(s) and run them through a workflow that will transform the data into important information that helps us make accurate, timely predictions.
Using a basic workflow of serially processing the files essentially breaks down because we run out of memory when processing these large files in our serverless process. KNIME’s standard ingestion process caches the results from each node, thereby taking up precious memory, the lifeblood of a KNIME workflow. The second challenge is that the downstream nodes of the workflow don’t begin until after the previous node completes and then reading the data serially. Because of these challenges I needed to find a new way to process these large datasets. My serverless workflow is limited to 8G of memory and ingesting these large files was causing performance issues due to memory constraints. My research led me to KNIME’s streaming feature. This powerful process allowed me to ingest and process gigabytes of data in minutes instead of hours, thereby allowing me to meet the user’s data ingestion and processing requirements.
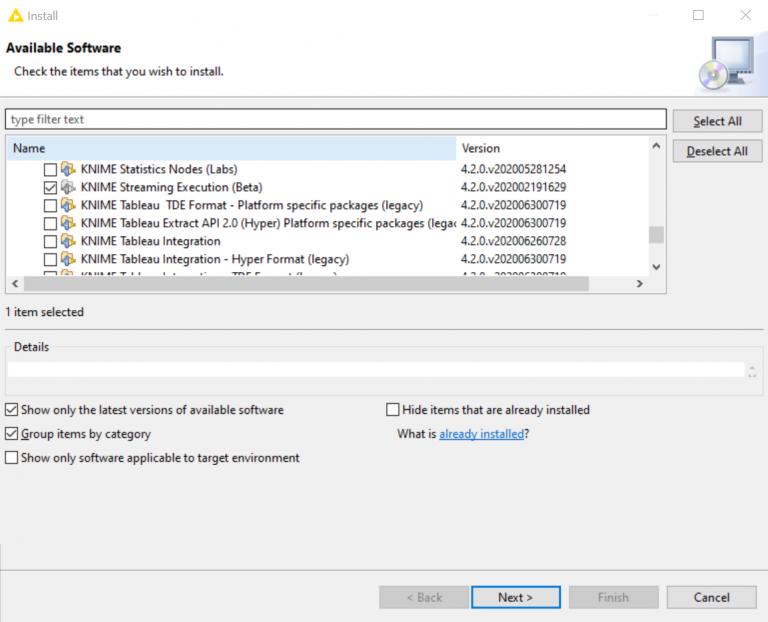
Let’s take a look at how to stream data using KNIME. First, you must install the KNIME streaming feature. For some reason KNIME does not install this feature as a part of the default installation, therefore you must install this feature manually. To do this go to File | Install KNIME Extensions and find the KNIME Labs Extensions and then look for KNIME Streaming Execution (Beta). Check the box and install this feature. I am uncertain why this is still defined as a Beta product because it has been around for years and works exactly as advertised.
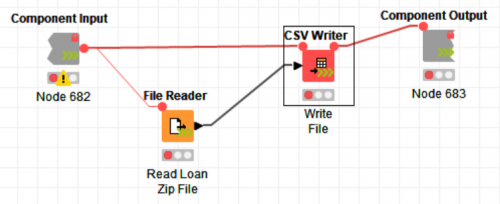
Now that you have the streaming functionality installed, we need to put this into action (literally). To use the streaming functionality, you need to encapsulate the part of the workflow that you want to stream into a component. For this blog, I created a simple workflow that reads a large zipped CSV file from a website and writes it to the default KNIME workflow location (KNIME://knime.workflow).
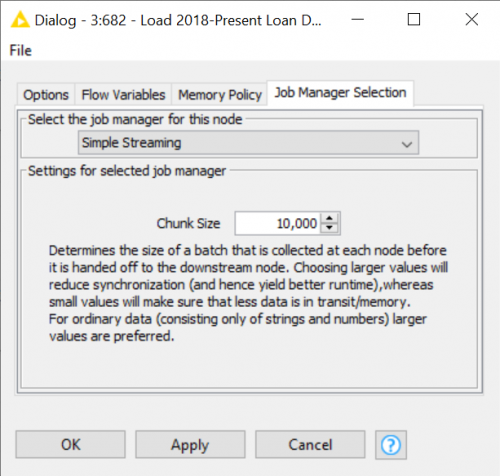
Next, we go out to the parent workflow and configure the component. There you will see several tabs. Go to the Job Manager Selection tab and change the job manager for this node to Simple Streaming. Then go and change the Chunk Size to your preferred batching size that meets your performance requirements.
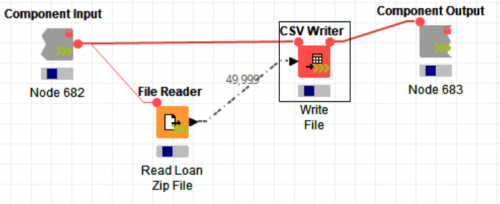
Finally, you run the workflow as normal. When you open the component you will see the data streaming through the nodes.